200+
internships found

A fully automated, cloud-native pipeline that continuously scans the web for finance, consulting, and aerospace engineering internship opportunities across eight European countries — with a deliberate focus on boutique and lesser-known firms where competition is lower. Built on Google Cloud Functions with Perplexity AI search and a Telegram bot interface, the system has surfaced over 200 opportunities since launch at a total infrastructure cost of $0.82.
200+
internships found
8
countries covered
$0.82
total cost since March 2026
Python, Google Cloud Functions, Telegram API, Perplexity API
Coding
Active
Independent Project
Manual internship hunting is slow, repetitive, and biased towards well-known firms - because those are the ones that show up in generic searches. This project replaces that process with an intelligent monitoring system that runs continuously in the background, proactively identifying and delivering relevant opportunities without any manual effort.
The bot covers management consulting, strategy consulting, investment banking, asset management, private equity, venture capital, hedge funds, and aerospace engineering roles across the UK, Belgium, Netherlands, France, Germany, Spain, Switzerland, and Italy. It targets penultimate-year undergraduate positions specifically, and deliberately prioritises boutique and SME firms alongside household names — the ones that are often overlooked but are significantly less competitive to apply to.
The system follows a modular, serverless design built on Google Cloud Functions. Five discrete endpoints handle different parts of the pipeline:
All endpoints are secured with environment variables. The entire system runs idle between scheduled triggers, keeping infrastructure costs near zero.
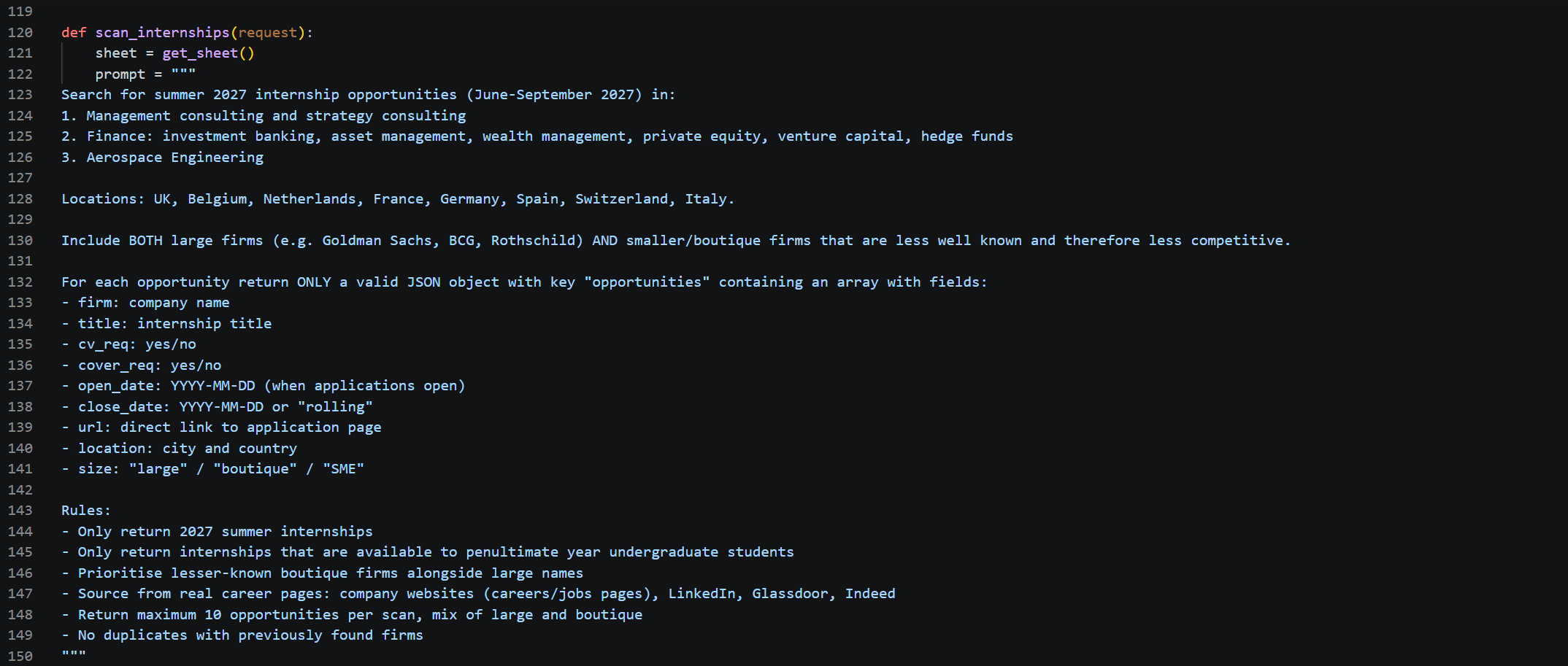
Each scan queries Perplexity AI's sonar-pro model with a structured prompt that requests a strict JSON response — no markdown, no preamble. The prompt specifies the target sectors, geographies, firm sizes, degree level, and year group, and instructs the model to source directly from company career pages, LinkedIn, Glassdoor, and Indeed. The system prompt enforces JSON-only output, and the response is parsed and validated before any data is written.
Each opportunity is returned with: firm name, role title, CV and cover letter requirements, application open and close dates, a direct URL to the application page, location, and firm size classification (large / boutique / SME).
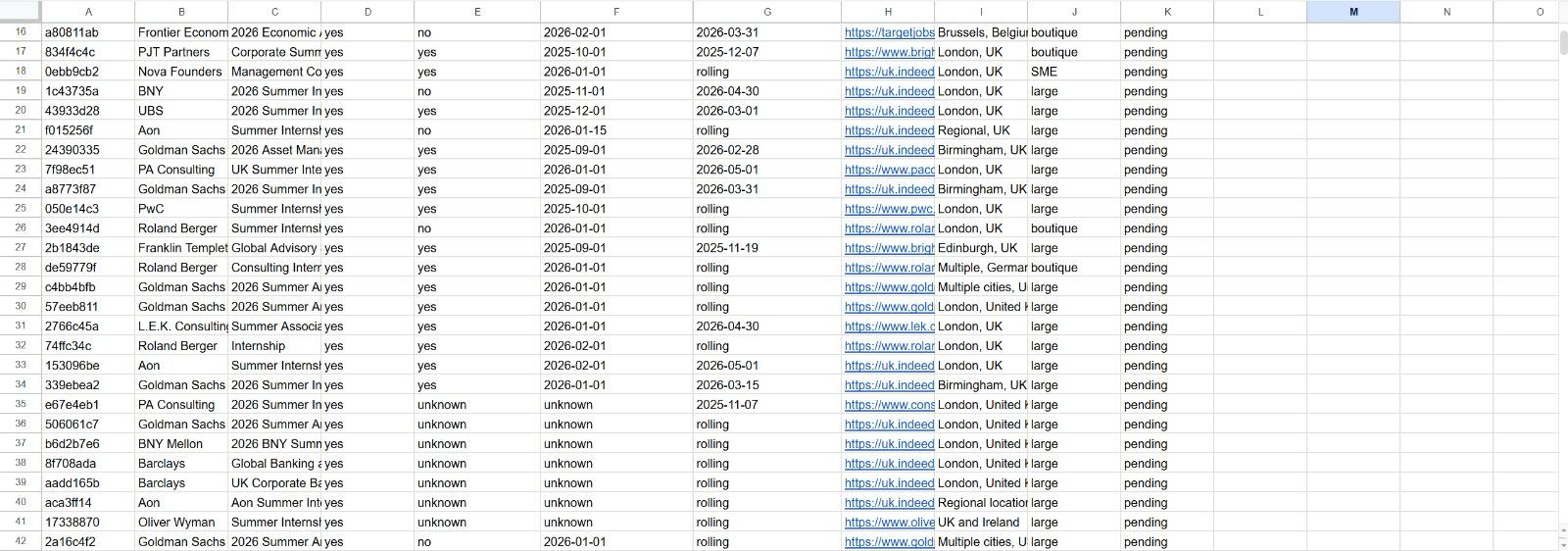
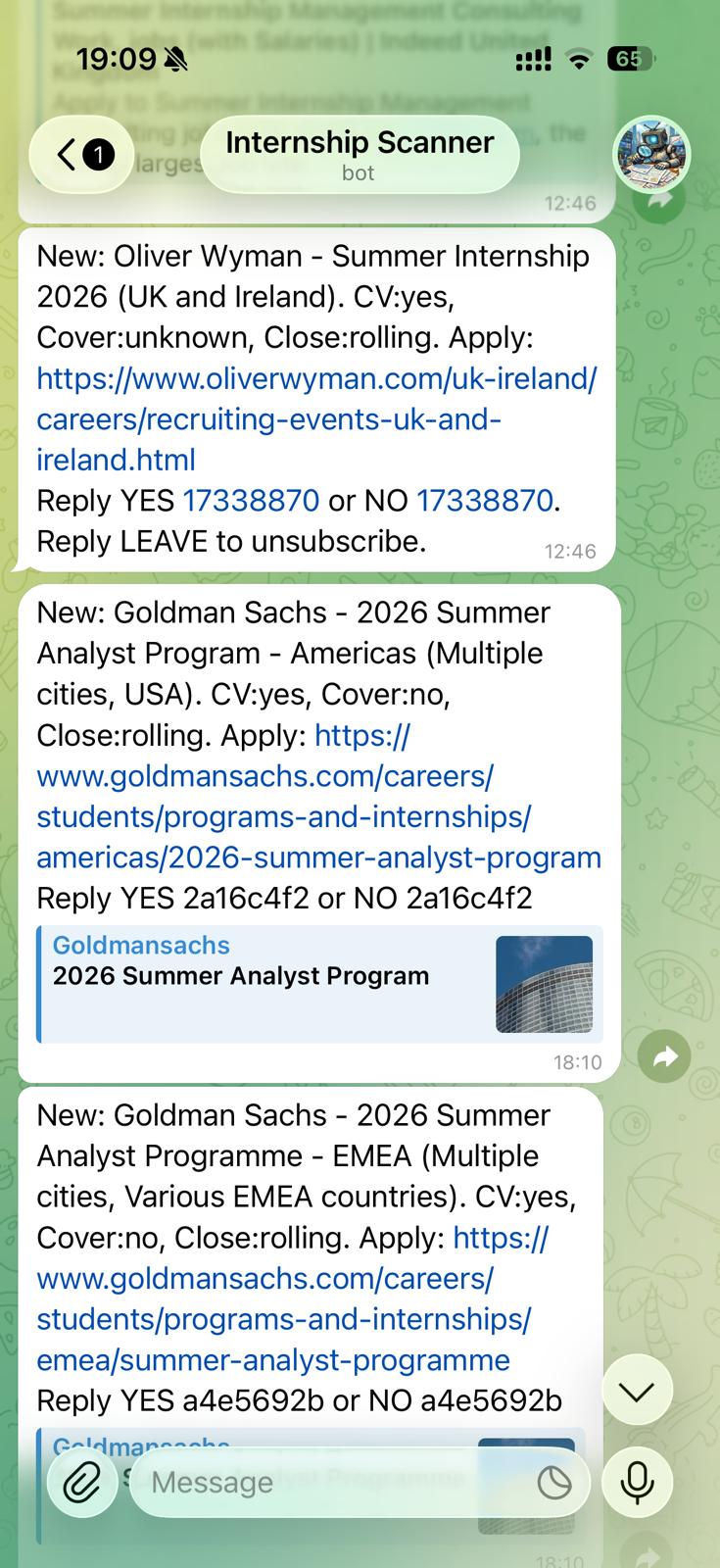
Because the system scans every three days, it frequently encounters listings that were already found in a previous cycle. A deduplication layer checks every incoming result against the full history of recorded entries in the Google Sheets database, matching on firm name and role title. Only genuinely new opportunities trigger a Telegram alert and a new database row.
Google Sheets serves as the persistent backend — storing opportunity IDs, firm and role details, application requirements, dates, URLs, firm size, status, and a per-opportunity record of which subscribers have saved it. This doubles as a lightweight admin dashboard, giving a live view of everything the system has found.